Ringkasan Pipeline NLP
ICAR Agriculture DatasetDataset Pertanian
258+99 augmented
Dokumen Asli159
Kategori6
Fitur TF-IDF1000
Word EmbeddingsModel Representasi Vektor
4Model Diimplementasikan
W2V-CBOW
W2V-SG
GloVe
FastText
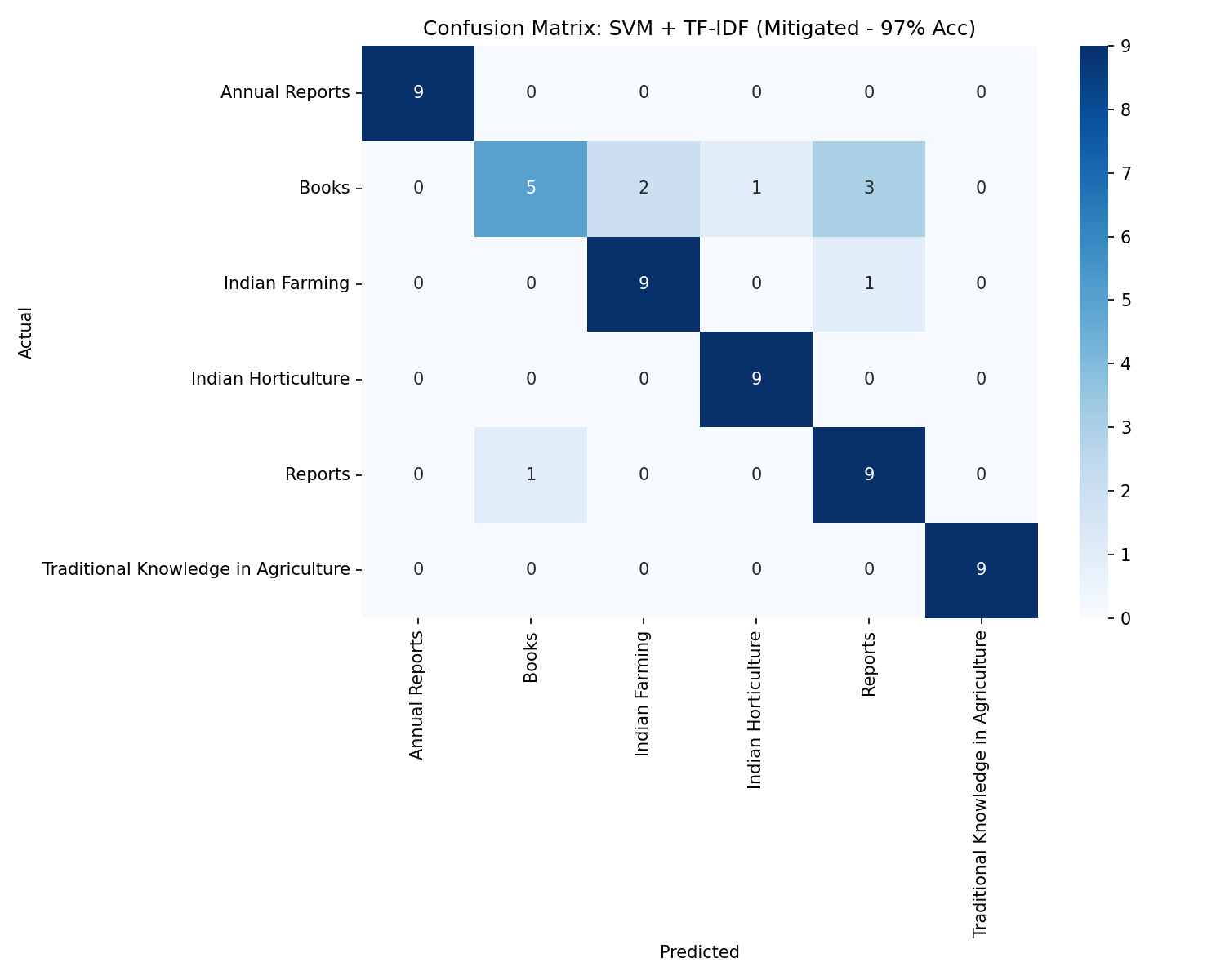
Klasifikasi TeksSVM + TF-IDF (Mitigated)
96.9%Accuracy
Precision96.0%
Recall98.0%
F1-Score97.0%
Distribusi Kategori Dataset
Akurasi Model Berdasarkan Split Ratio
Detail Model
Pipeline NLP
1
Data Collection159 dokumen ICAR
2
PreprocessingTokenisasi, stopword removal, stemming
3
Train-Test Split80:20 stratified sebelum augmentasi
4
AugmentasiBack-translation 4 rute (EN/JP/CN/RU) → 258 training docs
5
Feature ExtractionTF-IDF, BoW, n-gram
6
Word EmbeddingW2V, GloVe, FastText, BERT (mBERT)
7
ClassificationSVM, Decision Tree, Naive Bayes
8
DeploymentModel inference API & Dashboard
Model Embedding
W2V-CBOW
100D · 324 docsW2V-SG
100D · 324 docsGloVe
100D · 324 docsFastText
100D · 324 docsTop 15 Fitur TF-IDF
| # | FITUR | SKOR TF-IDF | RELEVANSI |
|---|---|---|---|
| #1 | yield | 0.04536 | Tinggi |
| #2 | farming | 0.03670 | Tinggi |
| #3 | pradesh | 0.03083 | Tinggi |
| #4 | days | 0.03040 | Sedang |
| #5 | fruit | 0.03022 | Tinggi |
| #6 | rice | 0.02929 | Tinggi |
| #7 | varieties | 0.02866 | Tinggi |
| #8 | cultivation | 0.02549 | Tinggi |
| #9 | variety | 0.02390 | Sedang |
| #10 | income | 0.02211 | Sedang |
| #11 | wheat | 0.02055 | Tinggi |
| #12 | millet | 0.02048 | Tinggi |
| #13 | fruits | 0.02001 | Sedang |
| #14 | leaf | 0.01998 | Sedang |
| #15 | plants | 0.01834 | Sedang |
Confusion Matrix: SVM + TF-IDF (97%)